Szórás (statisztika): definíció, jelentés és minta-számítás
Szórás (statisztika): világos definíció, jelentés és minta-számítás – gyakorlati példák, lépésről lépésre számítások és alkalmazások statisztikában és pénzügyben.
A szórás egy olyan szám, amely azt mutatja meg, hogy egy csoport mérései hogyan szóródnak az átlagtól (átlag) vagy a várható értéktől. Az alacsony szórás azt jelenti, hogy a legtöbb szám közel van az átlaghoz. A magas szórás azt jelenti, hogy a számok jobban szóródnak.
A bejelentett hibahatár általában a szórás kétszerese. A tudósok általában a számok átlagtól való szórását jelentik a kísérletek során. Gyakran úgy döntenek, hogy csak a szórás kétszeresénél vagy háromszorosánál nagyobb különbségek fontosak. A szórás a pénzügyekben is hasznos, ahol a megkeresett kamatok szórása megmutatja, hogy egy személy megkeresett kamatai mennyire térhetnek el az átlagtól.
Sokszor csak egy minta vagy egy csoport egy része mérhető. Ilyenkor az egész csoportra vonatkozó szóráshoz közeli számot lehet találni egy kissé eltérő egyenlet segítségével, amelyet minta szórásnak nevezünk, és amelyet az alábbiakban ismertetünk.
Képgaléria
2 Képek
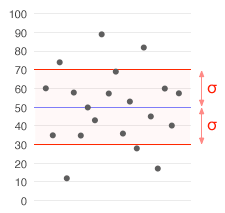
Mit mér pontosan a szórás?
Röviden: a szórás azt mutatja meg, hogy az egyes értékek átlagosan mennyire térnek el az átlagtól. Minél nagyobb a szórás, annál szélesebb a mérési eredmények eloszlása. A szórás négyzetének neve a variancia, amely a szórás négyzete. A variancia előnye, hogy algebrailag kényelmesebb, hátránya, hogy mértékegysége a négyzetes egység (például m²), ezért gyakran a szórást használjuk, mert annak mértékegysége megegyezik az eredeti adatoké.
Populációs és mintabeli szórás — képletek és miért különböznek
Populációs (teljes halmazra számolt) szórás:
σ = sqrt( (1/N) Σ (xi − μ)² )
Itt N az összes elem száma, μ a populáció átlaga, xi az egyes megfigyelések.
Minta szórása (amikor csak egy minta áll rendelkezésre):
s = sqrt( (1/(n−1)) Σ (xi − x̄)² )
Itt n a minta elemszáma, x̄ a mintaátlag. A nevezőben szereplő n−1-et Bessel-korrekciónak nevezik, és azért használjuk, mert így a minta varianciája torzítatlan becslést ad a populáció varianciájára.
Hogyan számoljuk ki lépésről lépésre?
- Számold ki az átlagot (populáció esetén μ, minta esetén x̄).
- Minden értéknél vond ki az átlagot, és négyzetre emeld a különbséget: (xi − átlag)².
- Összegezd ezeket a négyzeteket: Σ (xi − átlag)².
- Oszd el az összeget N-nel (populáció) vagy n−1–gyel (minta).
- Vedd a kapott érték négyzetgyökét — ez a szórás.
Egyszerű példa
Legyen a minta: 2, 4, 4, 4, 5, 5, 7, 9.
- Összeg = 40, n = 8, mintaátlag x̄ = 40/8 = 5.
- Négyzetes eltérések: (2−5)²=9, (4−5)²=1 (háromszor), (5−5)²=0 (kétszer), (7−5)²=4, (9−5)²=16. Összegük = 32.
- Populációs variancia esetén: 32/8 = 4 → σ = √4 = 2.
- Minta variancia esetén (Bessel-korrekció): 32/(8−1) = 32/7 ≈ 4,571 → s ≈ √4,571 ≈ 2,14.
Értelmezés és használat
- A szórás egy érthető mérték arra, hogy mennyire „szóródnak” az adatok. Például egy termék gyártási méreteinek kis szórása jobb minőség-ellenőrzést jelez.
- Normális eloszlásnál az adatok körülbelül 68%‑a esik ±1σ, 95% körül ±2σ, és 99,7% körül ±3σ tartományba (ez az ún. 68–95–99,7 szabály).
- Amikor kockázatot vagy megbízhatóságot értékelünk (például pénzügyekben), a nagyobb szórás nagyobb kockázatot jelenthet, mert az eredmények kevésbé kiszámíthatóak.
Mikor érdemes más mutatót használni?
Ha az adatok erősen torzítottak vagy sok kiugró érték van, a szórás érzékeny lehet ezekre. Ilyen esetekben érdemes megfontolni a mediánt és a medián abszolút eltérést (MAD), vagy robusztusabb statisztikákat, amelyek kevésbé érzékenyek a kiugrókra.
Összefoglalás
A szórás fontos és gyakran használt statisztikai mutató, amely megmutatja az adatok átlagtól való szóródását. Különbséget kell tenni populációs és mintabeli számítás között (n ill. n−1 nevező), és tudatosan kell alkalmazni, különösen, ha az adatok eloszlása nem normális vagy kiugró értékeket tartalmaz.



Alapvető példa
Tekintsünk egy olyan csoportot, amely a következő nyolc számot tartalmazza:
2 , , , 4,4 , , ,4 , 5, 5, 7{\displaystyle9 2,\ 4,\ 4,\ 4,\ 4,\ 5,\ 5,\ 7,\ 9} 
E nyolc szám átlaga (átlaga) 5:
2 + +4 + +4 + +4 + +5 + + + 5+ 7= 98{\displaystyle5 {\frac {2+4+4+4+4+5+5+7+9}{8}}=5} 
A populáció szórásának kiszámításához először meg kell találni a listában szereplő egyes számok átlagtól való eltérését. Ezután az egyes különbségek eredményét négyzetre kell szorozni:
(2 - 5) =2 ( - 3) = 2(95 -5 ) = 202( - 5) = ( 04- ) =2 ( - 1) =2 (15 - 5) =2 02( 04-5 ) =2 ( - ) = ( - 1) =2 (17 - 5) = 222( 44- 5) =2 ( - ) = ( - 1) = ( - ) =2 ( 19- 5) = 242{\displaystyle16 {\begin{array}{lll}(2-5)^{2}=(-3)^{2}=9&&(5-5)^{2}=0^{2}=0\\(4-5)^{2}=(-1)^{2}=1&&(5-5)^{2}=0^{2}=0\\(4-5)^{2}=(-1)^{2}=1&&(7-5)^{2}=2^{2}=4\\(4-5)^{2}=(-1)^{2}=1&&(9-5)^{2}=4^{2}=16\\\end{array}}} 
Ezután keresse meg ezeknek az értékeknek az átlagát (összeg osztva a számok számával). Végül vegyük ki a négyzetgyökét:
( +9 + +1 + +1 + +1 + + + 0+ 0+ 4)16 = 8{\displaystyle2 {\sqrt {\frac {(9+1+1+1+1+1+0+0+4+16)}{8}}}=2} 
A válasz a populáció szórása. A képlet csak akkor igaz, ha az a nyolc szám, amellyel kezdtük, a teljes csoportot jelenti. Ha ezek csak a véletlenszerűen kiválasztott csoport egy része, akkor az utolsó előtti lépés alján (nevezőjében) a 8 (ami n) helyett a 7-et (ami n) kell használnunk (ami n). Ekkor a válasz a minta szórása. Ezt nevezzük Bessel-korrekciónak.
További példák
Egy kicsit nehezebb, valós példa: Az Egyesült Államokban a felnőtt férfiak átlagos testmagassága 70", a szórás 3". A 3"-es szórás azt jelenti, hogy a legtöbb férfi (körülbelül 68%, normális eloszlást feltételezve) 3" magasabb vagy 3" alacsonyabb az átlagnál (67"-73") - egy szórással. Majdnem minden férfi (kb. 95%) magassága 6" magasabb és 6" alacsonyabb az átlagnál (64"-76") - két standard eltérés. A három standard eltérés a vizsgált mintapopuláció 99,7%-ának összes számát tartalmazza. Ez akkor igaz, ha az eloszlás normális (harang alakú).
Ha a szórás nulla lenne, akkor minden férfi pontosan 70" magas lenne. Ha a szórás 20" lenne, akkor egyes férfiak sokkal magasabbak vagy sokkal alacsonyabbak lennének az átlagnál, és a tipikus tartomány körülbelül 50"-90" lenne.
Egy másik példa: a három csoport {0, 0, 14, 14, 14}, {0, 6, 8, 8, 14} és {6, 6, 8, 8, 8} mindegyikének átlaga (átlaga) 7. De a szórásuk 7, 5 és 1. A harmadik csoport szórása sokkal kisebb, mint a másik kettőé, mert a számok mindegyike közel van 7-hez. Az alapgondolat az, hogy a szórás megmondja, hogy a többi szám mennyire tér el az átlagtól. Ugyanazok az egységek lesznek, mint maguknak a számoknak. Ha például a {0, 6, 8, 14} csoport egy négy testvérből álló csoport életkora években kifejezve, akkor az átlag 7 év, a szórás pedig 5 év.
A szórás a bizonytalanság mérésére szolgálhat. A tudományban például az ismételt mérések egy csoportjának szórása segít a tudósoknak abban, hogy tudják, mennyire biztosak az átlagos számban. Annak eldöntésekor, hogy egy kísérletből származó mérések egyeznek-e egy előrejelzéssel, e mérések szórása nagyon fontos. Ha a kísérletekből származó átlagos szám túl messze van a megjósolt számtól (a szórásban mért távolsággal), akkor a tesztelt elmélet lehet, hogy nem helyes. Lásd előrejelzési intervallum.
Alkalmazási példák
Egy értékkészlet szórásának megértése arra szolgál, hogy tudjuk, mekkora eltérés várható az "átlagtól" (átlagtól).
Időjárás
Egyszerű példaként nézzük meg két város napi átlaghőmérsékletét, egy belföldi és egy óceán melletti városét. Hasznos megérteni, hogy az óceánhoz közeli városok esetében a napi legmagasabb hőmérsékleti értékek tartománya kisebb, mint a szárazföld belsejében fekvő városok esetében. A két városnak lehet, hogy a napi legmagasabb átlaghőmérséklete megegyezik. A tengerparti város napi magas hőmérsékletének szórása azonban kisebb lesz, mint a szárazföldi városé.
Sport
Egy másik módja ennek, ha a sportcsapatokra gondolunk. Bármely sportágban vannak olyan csapatok, amelyek bizonyos dolgokban jók, másokban pedig nem. A legmagasabbra rangsorolt csapatok nem fognak sok különbséget mutatni a képességek között. A legtöbb kategóriában jól teljesítenek. Minél kisebb a képességeik szórása az egyes kategóriákban, annál kiegyensúlyozottabbak és következetesebbek. A nagyobb szórással rendelkező csapatok azonban kevésbé lesznek kiszámíthatóak. Egy olyan csapat, amely általában rosszul teljesít a legtöbb kategóriában, alacsony szórással fog rendelkezni. Egy olyan csapat, amely a legtöbb kategóriában általában jó, szintén alacsony szórással fog rendelkezni. Egy magas szórású csapat azonban lehet olyan csapat, amely sok pontot szerez (erős támadójáték), de hagyja, hogy a másik csapat sok pontot szerezzen (gyenge védekezés).
Ha megpróbáljuk előre tudni, hogy melyik csapat fog nyerni, akkor a különböző csapat-"statisztikák" szórásainak megnézésével is próbálkozhatunk. A várttól eltérő számok összevethetik az erősségeket a gyengeségekkel, hogy megmutassák, milyen okok lehetnek a legfontosabbak annak megállapításában, hogy melyik csapat fog nyerni.
A versenyzésben azt az időt mérik, ameddig egy versenyzőnek minden egyes körét be kell fejeznie a pályán. Az alacsony szórású köridővel rendelkező versenyző következetesebb, mint a nagyobb szórású versenyző. Ez az információ segíthet megérteni, hogyan csökkentheti egy versenyző a kör befejezéséhez szükséges időt.
Money
A pénzben a szórás azt a kockázatot jelentheti, hogy egy árfolyam emelkedik vagy csökken (részvények, kötvények, ingatlanok stb.). Jelentheti azt a kockázatot is, hogy az árak egy csoportja emelkedik vagy csökken (aktívan kezelt befektetési alapok, index befektetési alapok vagy ETF-ek). A kockázat az egyik oka annak, hogy döntést hozzunk arról, hogy mit vásároljunk. A kockázat egy olyan szám, amelyből az emberek megtudhatják, hogy mennyi pénzt kereshetnek vagy veszíthetnek. Minél nagyobb a kockázat, annál nagyobb lehet egy befektetés hozama a vártnál (a "plusz" szórás). Ugyanakkor egy befektetés a vártnál több pénzt is veszíthet (a "mínusz" szórás).
Például egy személynek két részvény közül kellett választania. Az A részvény az elmúlt 20 évben átlagosan 10 százalékos hozamot ért el, 20 százalékpontos szórással (pp). A B részvény átlagos hozama az elmúlt 20 évben 12 százalék volt, de a szórás magasabb, 30 százalékpontos. A kockázatra gondolva az illető úgy dönthet, hogy az A részvény a biztonságosabb választás. Bár lehet, hogy nem fog annyi pénzt keresni, de valószínűleg nem is fog sok pénzt veszíteni. A személy úgy gondolhatja, hogy a B részvény 2 százalékponttal magasabb átlaga nem éri meg a további 10 pp standard eltérést (a várható hozam nagyobb kockázata vagy bizonytalansága).
Szabályok a normális eloszlású számokra
A szórással kapcsolatos legtöbb matematikai egyenlet feltételezi, hogy a számok normális eloszlásúak. Ez azt jelenti, hogy a számok az átlagérték mindkét oldalán bizonyos módon eloszlanak. A normális eloszlást Gauss-eloszlásnak is nevezik, mivel Carl Friedrich Gauss fedezte fel. Gyakran haranggörbének is nevezik, mert a számok úgy szóródnak szét, hogy a grafikonon harang alakot vesznek fel.
A számok nem normális eloszlásúak, ha az átlagérték egyik vagy másik oldalán csoportosulnak. A számok lehetnek szétszórtak, és mégis normális eloszlásúak. A szórás azt mutatja meg, hogy a számok mennyire szóródnak szét.

Az átlag (átlag) és a szórás közötti kapcsolat
Egy adathalmaz átlagát (átlag) és szórását általában együtt írják. Így az ember megértheti, hogy mi az átlagos szám, és hogy a csoportban lévő többi szám milyen széles szórást mutat.
A számok egy csoportjának eloszlását a variációs együtthatóval is meg lehet adni, amely a szórás és az átlag hányadosa. Ez egy dimenziótlan szám. A variációs együtthatót gyakran megszorozzák 100%-kal, és százalékban írják le.
Történelem
A szóródás kifejezést először Karl Pearson használta írásban 1894-ben, miután előadásokon használta. A szórást az azonos gondolat korábbi elnevezései helyettesítéseként használta: Gauss például az átlagos hibát használta.
Kapcsolódó oldalak
- Pontosság és precizitás
- A minta mérete
Kérdések és válaszok
K: Mi az a standard eltérés?
V: A szórás egy olyan szám, amely azt mutatja meg, hogy egy csoport mérései hogyan szóródnak az átlagtól (átlag vagy várható érték).
K: Mit jelent az alacsony szórás?
V: Az alacsony szórás azt jelenti, hogy a legtöbb szám közel van az átlaghoz.
K: Mit jelent a magas szórás?
V: A magas szórás azt jelenti, hogy a számok jobban szóródnak.
K: Hogyan használják a szórást a pénzben?
V: A pénzben a megkeresett kamatok szórása azt mutatja, hogy egy személy megkeresett kamatai mennyire térhetnek el az átlagtól.
K: Mikor lehet egy csoportnak csak egy részét mérni?
V: Sokszor csak egy minta, vagy egy csoport egy része mérhető.
K: Hogyan ábrázolják a teljes csoport szórását?
V: Az egész csoport szórását a görög َ \displaystyle \sigma َ betűvel ábrázoljuk. .
K: Hogyan ábrázolják a minta szórását?
V: A minta szórását az s {\displaystyle s} jelöli.
Kapcsolódó cikkek
Szerző
AlegsaOnline.com Szórás (statisztika): definíció, jelentés és minta-számítás Leandro Alegsa
URL: https://hu.alegsaonline.com/art/93321
Források
- edupristine.com : "What is Standard Deviation"
- jeff560.tripod.com : "Earliest known uses of some of the words of mathematics"