Zipf-törvény (Zipf-eloszlás): a szavak és rangsorok gyakorisági elve
Zipf-törvény: hogyan határozza meg a szavak gyakorisági eloszlása és rangsora? Magyarázat, példák és alkalmazások nyelvben, városokban, gazdaságban.
A Zipf-törvény egy matematikai statisztika segítségével megfogalmazott empirikus törvény, amelyet George Kingsley Zipf nyelvészről neveztek el, aki először javasolta.
Zipf törvénye kimondja, hogy a használt szavak nagy mintája esetén bármely szó gyakorisága fordítottan arányos a gyakorisági táblázatban elfoglalt helyével. Tehát az n számú szó gyakorisága 1/n arányos.
Így a leggyakoribb szó körülbelül kétszer olyan gyakran fordul elő, mint a második leggyakoribb szó, háromszor olyan gyakran, mint a harmadik leggyakoribb szó, stb. Például az angol nyelv szavainak egyik mintájában a leggyakrabban előforduló szó, a "the", az összes szó közel 7%-át teszi ki (69 971 szót az alig több mint 1 millióból). Zipf törvényéhez hűen a második helyen álló "of" szó a szavak valamivel több mint 3,5%-át teszi ki (36 411 előfordulás), amelyet az "and" (28 852) követ. Mindössze körülbelül 135 szóra van szükség ahhoz, hogy egy nagy mintában a szavak felét kitegyük.
Ugyanez az összefüggés számos más, a nyelvtől független rangsorban is előfordul, például a különböző országok városainak népességi rangsorában, a vállalatok méretében, a jövedelmi rangsorban stb. Az eloszlás megjelenését a városok népesség szerinti rangsoraiban először Felix Auerbach vette észre 1913-ban.
Nem tudni, hogy Zipf törvénye miért érvényes a legtöbb nyelvre.
Képgaléria
3 Képek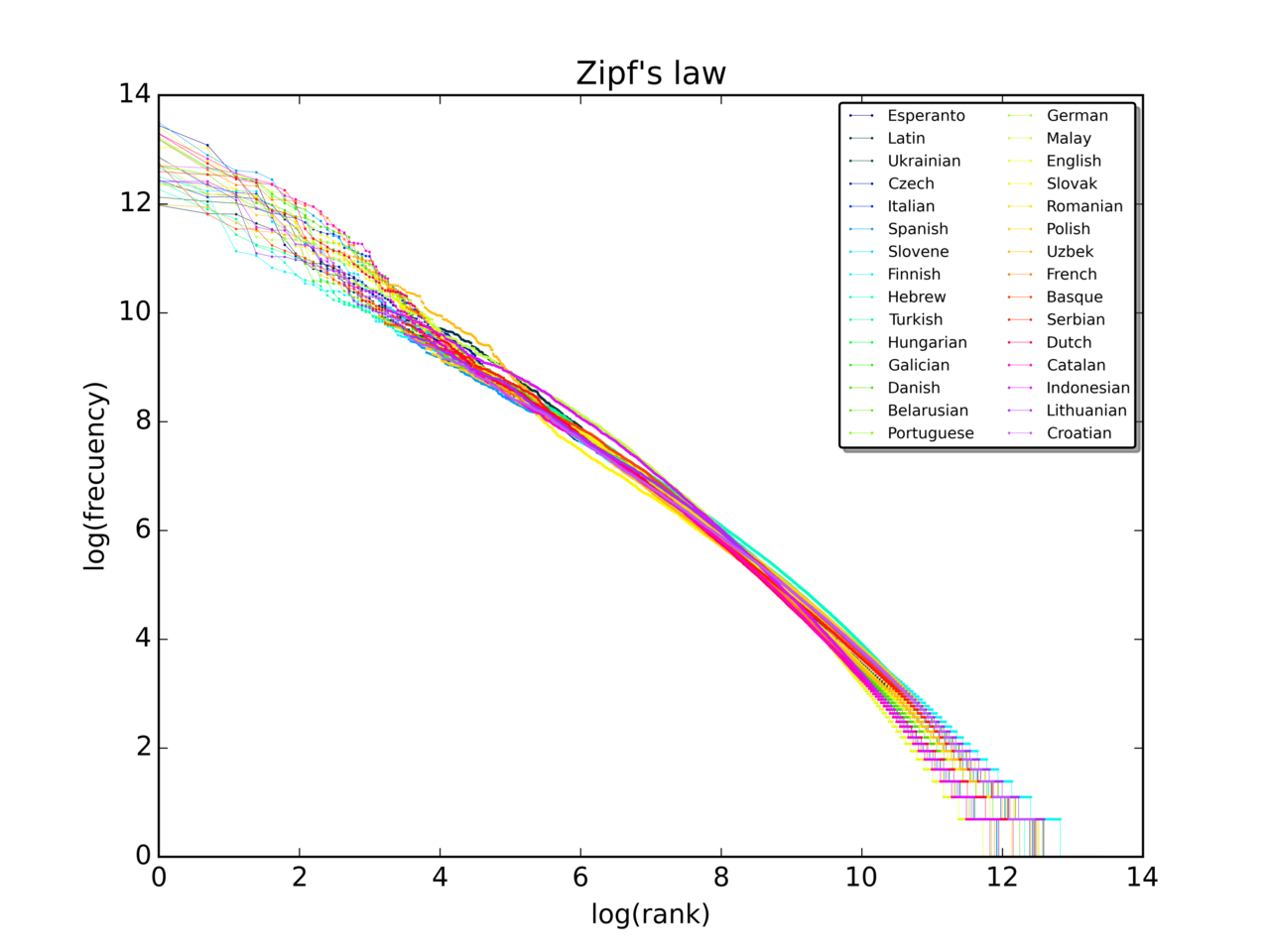


Matematikai leírás és variánsok
Általános alak: a rang–gyakoriság kapcsolatot gyakran a következő egyszerű hatványtörvénnyel írják le:
f(r) = C / r^s, ahol f(r) az r-edik rangú elem relatív gyakorisága, s az exponens (Zipf esetében közel 1), és C a normalizációs konstans.
A véges minták esetén C úgy számolható, hogy C = 1 / HN,s, ahol HN,s az általánosított harmonikus szám. Gyakori egyszerűsítés, amikor s = 1, ekkor beszélünk kifejezetten Zipf-törvényről.
Zipf–Mandelbrot terjesztés: Benoit Mandelbrot finomította a modellt egy eltolási paraméterrel:
f(r) = C / (r + q)^s, ahol q egy eltolás, amely jobb illeszkedést adhat valós adatoknál, különösen kis rangoknál.
Empirikus jelek és ábrázolás
A Zipf-jelenség könnyen felismerhető, ha a rangot és a gyakoriságot log–log skálán ábrázoljuk: egy hatványeloszlás ekkor megközelítőleg egyenes vonal lesz, meredeksége pedig −s. A valós nyelvi adatoknál az összevetés gyakran jó közelítést ad, de nem tökéletes; különösen a magas és alacsony rangoknál lehetnek eltérések.
A mintákban sok ritka szó fordul elő (ún. hapax legomena — egyszer előforduló szavak), ami a hosszú farok (heavy tail) jellegzetességéhez vezet. Ez fontos a szövegbányászatban és a nyelvi modellezésben.
Lehetséges magyarázatok
- Legkisebb erőfeszítés elve (Zipf): Zipf maga az emberi kommunikáció hatékonyságával indokolta, ahol a beszélők minimális erőfeszítéssel szeretnék átadni az információt, de a hallgatónak is értenie kell a mondandót — ez kompromisszumra vezet.
- Preferenciális csatolódás (Yule–Simon, Barabási–Albert): új elemek nagyobb valószínűséggel kapcsolódnak már gyakori elemekhez, ami hatványos eloszlást eredményez.
- Véletlen modellek: egyes egyszerű véletlen típusú modellek (pl. véletlen billentyűzet-nyomkodás) meglepő módon részben reprodukálhatnak hasonló mintázatot, bár ezek általában nem teljesen illeszkednek a nyelvi adatokra.
- Gazdasági és ökológiai mechanizmusok: sok olyan rendszer, ahol erőforrások eloszlása vagy növekedési folyamat játszik szerepet, hasonló skálafüggetlen viselkedést mutat.
Alkalmazások és következmények
Zipf-típusú eloszlások fontos szerepet játszanak:
- természetes nyelvek modellezése és nyelvi statisztikák megértése;
- információelméleti alkalmazások, például adattömörítés — a gyakori tokenek rövidebb kódot kaphatnak;
- városméretek, vállalatok nagysága, jövedelem-eloszlások és más társadalmi jelenségek analízise;
- keresőmotorok és rangsorolási problémák: gyakorisági minták segíthetik a prioritások kialakítását;
- forenzikus és stilometriai elemzések: szerzők, műfajok jellemző szókészlet-eloszlása.
Határok, kritikák és mérési módszerek
Bár a Zipf-törvény sok rendszernél jól szemlélteti a jelenséget, fontos tudni korlátait:
- Nem mindig pontos: az s értéke gyakran eltér 1-től; a kis és nagy rangoknál az illeszkedés gyengébb lehet.
- Mintanagyság és korlátok: véges korpuszoknál normalizációs és zajproblémák lépnek fel.
- Illesztés vizsgálata: log–log lineáris regresszió használata egyszerű, de torzíthat; helyesebb módszer a maximum likelihood estimáció (MLE) az exponens becslésére, majd jó illeszkedés tesztelése (például Kolmogorov–Smirnov teszttel), követve a Clauset–Shalizi–Newman ajánlásait.
Rövid történeti áttekintés
A jelenség korai megfigyelései közé tartozik Pareto munkája a jövedelmek eloszlásáról, Felix Auerbach 1913-as megfigyelése a városméretek rangsoráról, és később Zipf népszerűsítése a nyelvészetben. Benoit Mandelbrot finomította a modellt 1950-es években, míg 20. századi irodalom számos mechanisztikus magyarázatot és statisztikai vizsgálatot vezetett be.
Összefoglalás
A Zipf-törvény egy erőteljes, empirikus megfigyelés arról, hogy sok rendszernél a rang és a gyakoriság között hatványtörvényes kapcsolat áll fenn, gyakran közel az 1/r alakhoz. Bár pontos okai vitatottak és rendszerfüggők, a jelenség hasznos szemléletet ad nyelvi és társadalmi adatok elemzéséhez. A pontos vizsgálathoz és értelmezéshez mindig érdemes statisztikai teszteket és alternatív modelleket is alkalmazni.
Kérdések és válaszok
K: Mi az a Zipf-törvény?
V: A Zipf-törvény egy empirikus törvény, amely kimondja, hogy egy szó gyakorisága egy nagy mintában fordítottan arányos a gyakorisági táblázatban elfoglalt helyével.
K: Ki javasolta Zipf törvényét?
V: A Zipf-törvényt először George Kingsley Zipf nyelvész javasolta.
K: Hogyan magyarázza Zipf törvénye a szavak gyakoriságát egy angol szavakból álló mintában?
V: Zipf törvénye szerint az angol szavak mintájában a leggyakoribb szó körülbelül kétszer olyan gyakran fordul elő, mint a második leggyakoribb szó, háromszor olyan gyakran, mint a harmadik leggyakoribb szó stb. Ez a tendencia a szó rangjának csökkenésével folytatódik.
K: Az összes szó hány százalékát teszi ki a leggyakrabban előforduló szó az angol szavak egy mintájában?
V: Az angol szavak egyik mintájában a leggyakrabban előforduló szó ("the") az összes szó közel 7%-át teszi ki.
K: Milyen összefüggés van a minta felét kitevő szavak száma és e szavak gyakorisága között?
V: Zipf törvénye szerint egy nagy mintában a szavak felének számbavételéhez csak körülbelül 135 szóra van szükség.
K: Milyen más rangsorok mutatják Zipf törvényét?
V: Ugyanaz az összefüggés, amelyet a Zipf-törvény a szavak gyakoriságában leír, más, a nyelvtől független rangsorokban is előfordul, például a különböző országok városainak népességi rangsorában, a vállalatok méretében és a jövedelmi rangsorokban.
K: Ki vette észre az eloszlás megjelenését a városok népesség szerinti rangsoraiban?
V: Az eloszlás megjelenését a városok népesség szerinti rangsorában először Felix Auerbach vette észre 1913-ban.
Kapcsolódó cikkek
Szerző
AlegsaOnline.com Zipf-törvény (Zipf-eloszlás): a szavak és rangsorok gyakorisági elve Leandro Alegsa
URL: https://hu.alegsaonline.com/art/110649
Források
- books.google.com : P. 139