Gyorsítótár-algoritmusok: definíció és áttekintés (LRU, LFU, ARC)
Gyorsítótár-algoritmusok áttekintése: LRU, LFU, ARC működése, előnyei és implementálási tippek a találati arány és késleltetés optimalizálásához.
A gyorsítótár algoritmus olyan szabályrendszer, amely egy gyorsítótár (cache) tartalmának kezelésére szolgál: eldönti, mely elemeket kell megtartani és melyeket eltávolítani, amikor a gyorsítótár megtelik. A cél általában a találati arány maximalizálása (hány kérést tud kiszolgálni a cache) és a késleltetés minimalizálása (mennyi idő alatt érjük el a cache-ben tárolt elemet). A gyorsítótár algoritmusok e két szempont között keresnek kompromisszumot, figyelembe véve a rendelkezésre álló memóriát és a hozzáférési mintázatokat. Az ideális (optimális) elv az lenne, ha mindig azokat az elemeket törölnénk, amelyekre a jövőben a leghosszabb ideig nem lesz szükség: ezt a megoldást Belady optimális algoritmusának vagy clairvoyant algoritmusnak nevezik. Mivel a jövő előrejelzése általában nem lehetséges, a gyakorlatban heuristikák és adaptív módszerek használatosak; az egyes algoritmusok teljesítményét gyakran ezen optimális alsó határhoz viszonyítják.
Képgaléria
7 Képek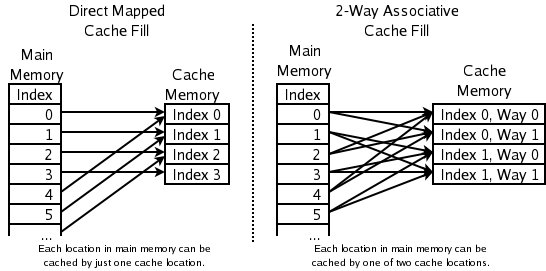



Gyakori gyorsítótár-elvek és algoritmusok
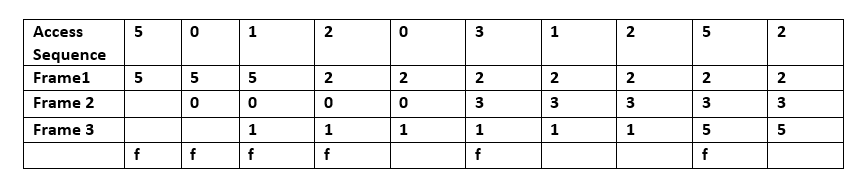
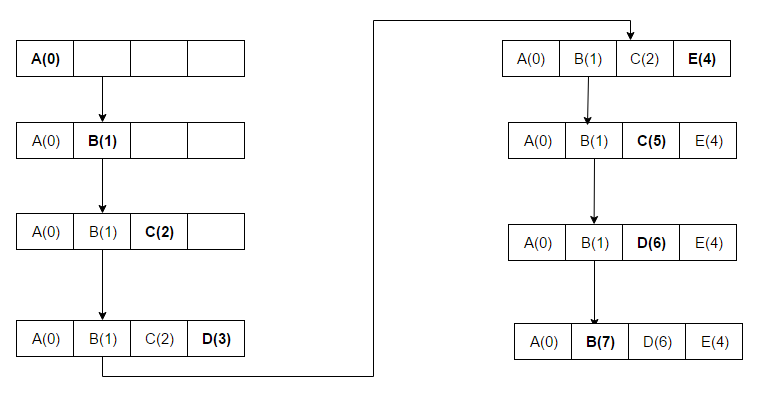
- Legkevésbé nemrégiben használt (LRU): azokat az elemeket távolítja el, amelyekhez a leghosszabb ideje nem fértek hozzá. Az LRU megvalósításai gyakran fenntartanak egy sorrendet (pl. láncolt lista plusz hash táblát), hogy a hozzáférések frissítése és az eltávolítás amortizáltan O(1) legyen. Az LRU egy családot is jelöl a gyakorlatban: például a Theodore Johnson és Dennis Shasha által javasolt 2Q és a Pat O'Neil, Betty O'Neil és Gerhard Weikum által fejlesztett LRU-K is az LRU alapelvén alapul, de kiegészítik azt további információk (pl. korábbi hozzáférések száma vagy több front) figyelembevételével. a gyorsítótárazási algoritmusok egy családja
- Legutóbb használt / legutoljára hozzáfért (MRU): ennek az algoritmusnak stratégiai alkalmazása során először a legutóbb használt elemeket dobják ki. Ez hasznos lehet olyan mintázatoknál, ahol a legutóbb használt elemhez rövid időn belül nem lesz újra szükség (például bizonyos adatbázis-műveleteknél). adatbázisok memóriakezelésében néha előfordul.
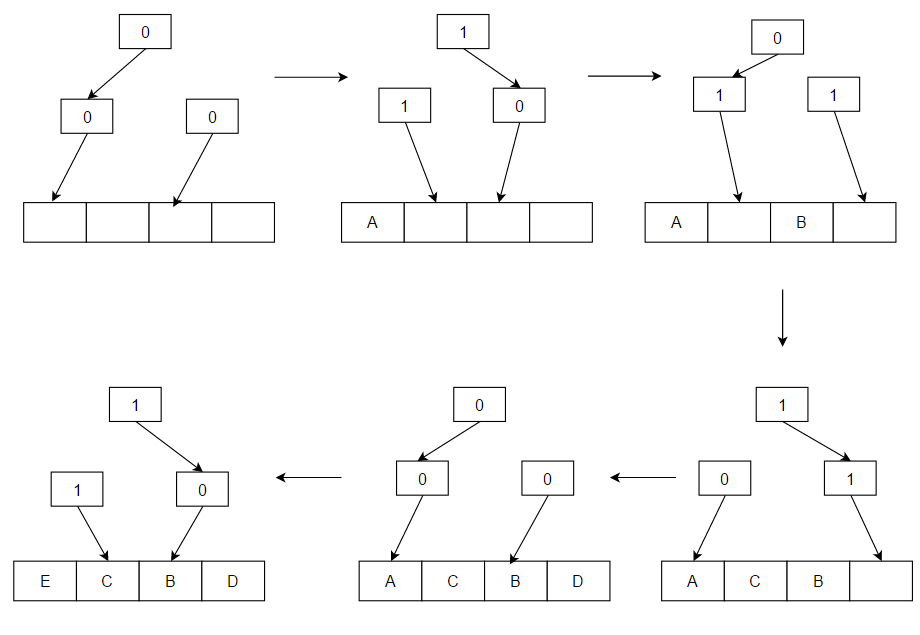
- Pszeudo-LRU (PLRU): bizonyos környezetekben (pl. nagysebességű CPU-cache-eknél) az LRU pontos megvalósítása túl költséges lehet. A PLRU egyszerűbb, kevésbé pontos helyettesítési döntéseket hoz, és elemenként általában csak egy kis számú bitet (pl. egy bit vagy fa-struktúra) használ. Ez gyors és memóriahatékony, de nem mindig ad optimális találati arányt.
- 2-way set associative: a CPU-cache-eknél gyakori megoldás; az új blokk címe alapján kiszámítják, hogy a cache melyik szettjébe tartozik, és azon a szetten belül két hely közül választhatnak. A kettő közül általában az LRU elv alapján döntik el, melyiket távolítsák el; szett szinten egy bit (vagy egyszerű jelző) jelöli a „régebb használt” sort.
- Közvetlen leképezésű gyorsítótár (direct-mapped): az egyik leggyorsabb megoldás, ahol egy cím pontosan egy helyhez tartozik a cache-ben. Ha új elem érkezik ugyanarra a helyre, a korábban ott lévőt törölni kell. Nagy sebességet ad, de ütközések (conflict misses) gyakrabban fordulnak elő.
- Legkevésbé gyakran használt (LFU): az egyes elemekhez számlálót tart fenn, amely növekszik a hozzáférések számlálásával; azokat az elemeket dobja el először, amelyeket a legkevesebbszer kértek. Az LFU jól működik, ha a gyakoriság a jövőbeli hasznosság jó előrejelzője, de problémát jelenthet, ha egy elem egyszer nagyon népszerű volt, majd soha többé nem használják — ezért gyakori a számlálók „öregedésének” (decay) vagy újrasúlyozásának bevezetése.
- Adaptive Replacement Cache (ARC): adaptív módon egyensúlyozza a recencia (LRU-szerű viselkedés) és a gyakoriság (LFU-szerű viselkedés) között annak érdekében, hogy különböző access mintázatoknál jobb kombinált teljesítményt érjen el. Az ARC dinamikusan állítja a recencia/frekvencia részlegek méretét és kiegészítő „ghost” listákat tart, hogy tanulja a munkakészlet jellemzőit. (Az ARC-t Nimrod Megiddo és Dror Modha dolgozta ki.)
- 2Q, LRU-K, Multi Queue (MQ): több, a gyakorlatban bevált variáns és hibrid algoritmus létezik. A 2Q (Johnson & Shasha) két queue-val különbözteti meg az egyszeri és ismételt hozzáféréseket; az LRU-K a K. legutóbbi hozzáférés információját használja; a MQ (Y. Zhou, J.F. Philbin és Kai Li) több sorból álló struktúrát használ a különböző gyakorisági/recencia szintek elkülönítésére.
Implementációs és gyakorlati megfontolások
- Teljesítmény és költség: az algoritmus kiválasztása gyakran a CPU-idő, memóriahasználat és a szükséges komplexitás függvénye. Az LRU pontos megvalósítása drágább lehet (szinkronizáció, frissítések), míg a PLRU vagy egyszerű bitek olcsóbbak gyors, hardware-s környezetben.
- Tárgyak különböző költségei: ha egy elem lekérése (vagy újraprodukálása) költséges, érdemes megtartani azt a cache-ben, még akkor is, ha ritkábban használják. Ezt figyelembe vevő politikákat (cost-aware caching) lehet alkalmazni.
- Változó méretek: ha az elemek eltérő méretűek, a hagyományos „egység helyek” feltétele nem működik; ilyenkor a cache „érték / méret” arányát is figyelembe vehetjük az eltávolításnál.
- Idővel lejáró tételek (TTL): webes cache-eknél, DNS-cache-eknél vagy hírcache-eknél gyakori, hogy az adatoknak van érvényességi ideje. Ilyenkor a lejárat egyszerű és hatékony szűrési módszer lehet a gyorsítótár karbantartására, és csökkentheti a helyettesítési algoritmusok igényét.
- Lopakodó hatások és „cache pollution”: dinamikus munkaterhelésnél előfordulhat, hogy ritkán használt, de egyszerre sok helyet foglaló elemek ideiglenesen rontják a találati arányt. Külön stratégiák (például nagy elemek speciális kezelésével) csökkenthetik ezt a problémát.
- Időbeli súlyozás (decay / aging): LFU típusú algoritmusoknál fontos lehet a történeti számlálók időbeli gyengítése, hogy a korábban népszerű, de jelenleg nem használt elemek ne tartsanak fenn túl sokáig egy korlátos cache-t.
- Hardver-specifikus megoldások: CPU cache-ekben (L1/L2/L3) gyakran alkalmaznak egyszerű, nagyon gyors megoldásokat (pl. direct-mapped, 2-way, PLRU, tree-PLRU), míg szoftveres cache-ek (adatbázis, web-cache) gazdagabb információt használó és adaptív stratégiákat részesítenek előnyben.
- Hatékonyság mérés: a gyorsítótárak teljesítményét általában találati arány, miss-rate, átlagos hozzáférési késleltetés és erőforrás-használat alapján mérik. Tesztelés valós vagy szintetikus munkaterhelésekkel szükséges a jó politika kiválasztásához.
Végezetül, amikor több, egymástól független gyorsítótár is ugyanazon adatokhoz fér hozzá (például több adatbázis-kiszolgáló vagy több cache-lépcső), fontos a gyorsítótárak koherenciájának fenntartása — erre különböző protokollok és algoritmusok léteznek. Ez csak olyan helyzetekre vonatkozik, amikor több független gyorsítótárat használnak ugyanazon adatokhoz (például több adatbázis-kiszolgáló frissíti az egyetlen közös adatfájlt). További részletek a gyorsítótárak koherenciájának kezeléséről találhatók.

Kérdések és válaszok
K: Mi az a gyorsítótár algoritmus?
V: A gyorsítótár algoritmus egy gyorsítótár vagy adatcsoport kezelésére használt algoritmus. Ez dönti el, hogy melyik elemet kell törölni a gyorsítótárból, amikor az megtelt.
K: Mi a találati arány?
V: A találati arány azt írja le, hogy egy kérést milyen gyakran lehet kiszolgálni a gyorsítótárból.
K: Mit ír le a késleltetés?
V: A késleltetés azt írja le, hogy mennyi idő alatt érhető el a gyorsítótárban tárolt elem.
K: Mi a Belady-féle optimális algoritmus?
V: A Belady optimális algoritmusa, más néven clairvoyant algoritmus, egy hatékony gyorsítótárazási algoritmus, amely mindig elveti azokat az információkat, amelyekre a jövőben a leghosszabb ideig nem lesz szükség. Ez az eredmény általában nem valósítható meg a gyakorlatban, mert meg kell jósolni, hogy mire lesz szükség messze a jövőben.
K: Hogyan működik az LRU (Least Recently Used)?
V: Az LRU először a legkevésbé használt elemeket törli, és az egyes gyorsítótár-sorok "korbitjeinek" használatával követni kell, hogy mit mikor használtak, és a korbitek alapján nyomon kell követni, hogy melyik volt a legkevésbé használt. Minden egyes alkalommal, amikor egy gyorsítótár-sort használnak, az összes többi gyorsítótár-sor kora ennek megfelelően módosul.
K: Hogyan működik a Legutóbb használt (MRU)?
V: Az MRU először a legutóbb használt elemeket törli, és ezt a gyorsítótárazási mechanizmust általában adatbázis-memória gyorsítótárakban használják.
K: Milyen más algoritmusok léteznek a gyorsítótár-koherencia fenntartására?
V: Különböző algoritmusok léteznek a gyorsítótár-koherencia fenntartására, amikor több független gyorsítótárat használnak megosztott adatokra, például több adatbázis-kiszolgáló frissít egy közös adatfájlt.
Kapcsolódó cikkek
Szerző
AlegsaOnline.com Gyorsítótár-algoritmusok: definíció és áttekintés (LRU, LFU, ARC) Leandro Alegsa
URL: https://hu.alegsaonline.com/art/15882
Források
- usenix.org : usenix.org/legacy/events/fast03/tech/full_papers/megiddo/megiddo.pdf
- usenix.org : usenix.org