Szuperskalár processzor: definíció, működés és előnyök
Szuperskalár processzor: áttekintés az utasításszintű párhuzamosításról, működésről és előnyökről; hogyan növeli a teljesítményt és mik a gyakorlati alkalmazások.
A szuperskalár CPU-tervezés az párhuzamos számítás olyan formája, pontosabban utasításszintű párhuzamosítást megvalósító megközelítése, amely lehetővé teszi, hogy egyetlen CPU-mag egy órajelen belül több utasítást hajtson végre. Gyakorlati értelemben ez azt jelenti, hogy a processzor több, egymástól független utasítást indít el és futtat párhuzamosan a duplikált funkcionális egységeken — például több aritmetikai logikai egység (ALU), lebegőpontos egység (FPU), vagy szorzó jelenlétével — az utasítás-diszpécselés segítségével.
Képgaléria
2 Képek
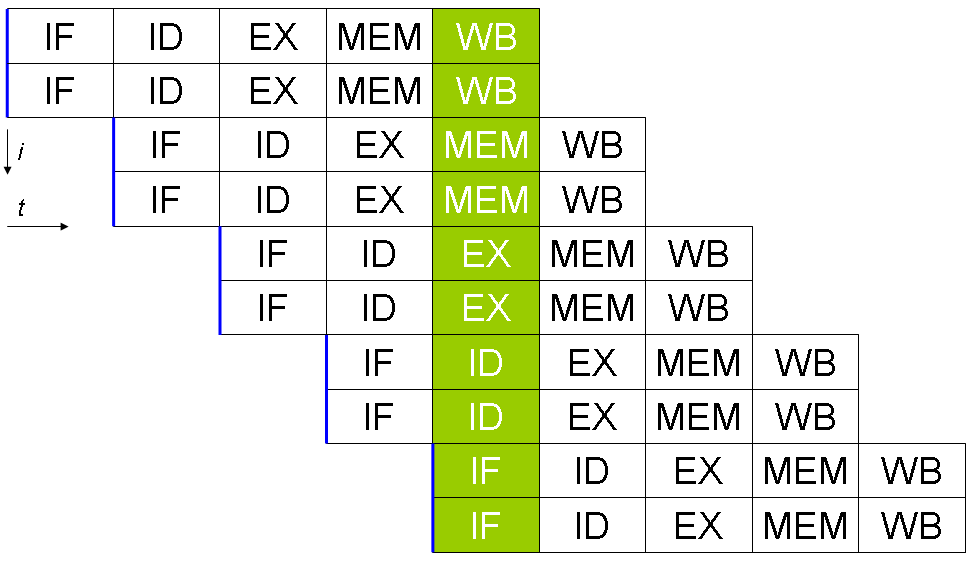
Működés, alapfogalmak
A szuperskalár működésének központi elemei:
- utasítás-felvétel (fetch): az utasítások sorozata egy rendezett utasításlistából (programkód) származik;
- dekódolás és függőség-felismerés: a CPU hardvere elemzi az utasítások közti adat- és vezérlési függőségeket, hogy eldöntse, melyek indíthatók egyszerre;
- utasításkiosztás (issue): az egyidejűleg végrehajtható utasításokat az utasításdiszpécser elküldi a rendelkezésre álló funkcionális egységekre;
- végrehajtás (execute): a funkcionális egységek elvégzik az adott műveleteket;
- commit/retire: a végrehajtott utasítások eredményeit sorrendileg vagy biztonságosan rögzítik a regiszterekben és a memóriában.
A legtöbb modern szuperskalár CPU pipeline-olt is, vagyis az egyes végrehajtási lépések (fetch, decode, execute, write-back stb.) egymásra fedve működnek a nagyobb órajelkihasználás érdekében. Elméletileg azonban létezhet pipeline nélküli szuperskalár, illetve pipeline-os, de nem szuperskalár architektúra is.
Mi különbözteti meg a skalár-, vektor- és szuperskalár processzorokat?
A skalárprocesszorok utasításonként általában egy vagy két adatelemet dolgoznak fel, míg a vektorprocesszorok egy utasítással egyszerre sok adatelemet (tömböket) kezelnek. A szuperskalár architektúra e kettő kombinációjának tekinthető:
- Minden utasítás tipikusan egy logikai adatelemet dolgoz fel;
- A CPU-magban azonban több, párhuzamosan működő, duplikált funkcionális egység található, így több utasítás egyszerre több, független adatelemet kezelhet.
Fontos belső elemek és technikák
- Utasításdiszpécser (issue logic): olvassa az utasításokat és dönt arról, melyek indíthatók párhuzamosan;
- Függőségkezelés: adatfüggőségek (RAW, WAR, WAW), vezérlési (branch) és strukturális függőségek felismerése és kezelése;
- Regiszter-átnevezés (register renaming): álcázza a kötések egy részét, hogy csökkentse a mesterséges függőségeket (WAW, WAR);
- Out-of-order végrehajtás és reorder buffer: az utasítások nem feltétlenül sorrendben hajtódnak végre, de a commit sorrendiségét megőrzik;
- Tomasulo, reservation stations, scoreboard: dinamikus kiosztó és ütemező mechanizmusok a függőségek és erőforrások kezelésére;
- Branch prediction: elágazások előrejelzése a pipeline telítettségének fenntartása miatt;
- Instruction fetch/width: hogy óraciklusonként mennyi utasítást képes betölteni és dekódolni a processzor (fetch/decode/issue width) — a nagyobb szélesség elméletben több párhuzamosságot tesz lehetővé.
Kihívások és korlátok
Bár a szuperskalár tervezés növeli az utasítások egy órajelciklus alatti számát (IPC — instructions per cycle), több korlát is csökkentheti a hasznos párhuzamosságot:
- Adatfüggőségek: ha egy későbbi utasítás egy korábbi eredményre vár, a párhuzamosítás korlátozott;
- Vezérlési függőségek és branch mispredictions: hibás elágazás-előrejelzés esetén a spekulatívan végrehajtott utasításokat vissza kell vonni, ez idő- és energiapazarlás;
- Memória-latencia: hosszú memóriamegállások (cache miss) lefoglalják az erőforrásokat és csökkentik a párhuzamosítható munkát;
- Strukturális korlátok: nincs elég funkcionális egység vagy port egyidejűleg; a hardver költsége, mérete és fogyasztása növekszik a szélesebb duplikációval;
- Párhuzamosság felső határa: csak a program belső párhuzamossága (ILP) határozza meg, mennyi utasítást lehet ténylegesen párhuzamosítani — egy adott programon belül ez gyakran korlátozott.
Előnyök
- nagyobb utasításonkénti áteresztőképesség (magasabb IPC), jobb CPU-hatékonyság;
- a pipelininggel kombinálva jelentős órajelenkénti teljesítménynövekedés érhető el;
- rugalmasabb, dinamikus erőforrás-kihasználás a különböző programozási mintázatokhoz;
- általános célú teljesítményjavulás, anélkül hogy a programozóknak speciális vektorutasításokat kellene használniuk.
Gyakorlati megjegyzések és történeti áttekintés
A szuperskalár megközelítést már több évtizede alkalmazzák a mikroprocesszorokban; az elmúlt évtizedek során gyakorivá vált, hogy az általános célú processzorok legalább néhányutas (többutas) szuperskalár kialakítással rendelkeznek. Egy tipikus, asztali vagy mobil CPU ma több ALU-t, FPU-t és esetenként SIMD egységet is tartalmazhat — a konkrét szám gyártótól és tervezéstől függ. A tervezés során a cél az, hogy az utasításelosztó pontosságát és intelligenciáját növelve minél folyamatosabban legyenek lefoglalva a funkcionális egységek; ha a diszpécser nem tud elegendő utasítást ütemezni, a szuperskalár előnyök nem realizálódnak és a CPU teljesítménye alacsonyabb lesz.
Összehasonlítás más megközelítésekkel
A szuperskalár technika különbözik más párhuzamosítási módszerektől:
- VLIW (Very Long Instruction Word): a párhuzamosságot a fordító határozza meg és kódolja a hosszú utasításokba, míg a szuperskalár hardver dinamikusan dönt a párhuzamosságról;
- SIMD: adat-paralelizmus egy utasításon belül (egyszerre sok adat), míg a szuperskalár több utasítást futtat párhuzamosan;
- SMT (Simultaneous Multithreading): több szál utasításainak egyidejű futtatása ugyanazon a magon; ez más megközelítés a funkcionális egységek teljesebb kihasználására.
Összegzés
A szuperskalár architektúra a modern CPU-tervezés egyik alapvető technikája, amely lehetővé teszi több utasítás párhuzamos végrehajtását egyetlen magon belül. Működése a függőségek felismerésén, intelligens utasítás-diszpécselésen és különféle mikrotechnikai megoldásokon (pl. regiszter-átnevezés, out-of-order végrehajtás, branch prediction) alapul. Bár jelentős teljesítményelőnyt ad, hatékonyságát programfüggőségek, memóriálatenciák és hardveres korlátok is behatárolhatják.


Korlátozások
A szuperskalár CPU-k tervezésénél a teljesítmény javulását két dolog korlátozza:
- A beépített párhuzamosság szintje az utasításlistában
- A diszpécser és az adatfüggőség-ellenőrzés összetettsége és időigénye.
Még ha végtelenül gyors függőségi ellenőrzés is van egy normál szuperskalár CPU-n belül, ha maga az utasításlista sok függőséget tartalmaz, ez szintén korlátozza a lehetséges teljesítményjavulást, így a kódban beépített párhuzamosság mennyisége egy másik korlátot jelent.
Nem számít, milyen gyors a diszpécser sebessége, van egy gyakorlati korlátja annak, hogy hány utasítást lehet egyszerre feladni. Bár a hardveres fejlődés lehetővé teszi, hogy CPU-magonként több funkcionális egység (pl. ALU) legyen, az utasításfüggőségek ellenőrzésének problémája olyan mértékben növekszik, hogy az elérhető szuperskaláris diszpécserhatár némileg kicsi. -- Valószínűleg öt-hat egyidejűleg feladott utasítás nagyságrendje.
Alternatívák
- A szimultán többszálú futás: gyakran SMT-ként rövidítik, a szuperskalár CPU-k általános sebességének növelésére szolgáló technika. Az SMT lehetővé teszi több független végrehajtószál használatát a modern szuperskalár processzoron belül rendelkezésre álló erőforrások jobb kihasználása érdekében.
- Többmagos processzorok: A szuperskalár processzorok abban különböznek a többmagos processzoroktól, hogy a több redundáns funkcionális egység nem teljes processzor. Egyetlen szuperskalár processzor olyan fejlett funkcionális egységekből áll, mint az ALU, az egész szám szorzó, az egész szám átváltó, a lebegőpontos egység (FPU) stb. Minden funkcionális egységnek több változata is lehet, hogy lehetővé tegye sok utasítás párhuzamos végrehajtását. Ez eltér a többmagos processzoroktól, amelyek több szálból származó utasításokat dolgoznak fel egyidejűleg, magonként egy szál.
- Pipelines processzorok: A szuperskalár processzorok szintén különböznek a pipelines CPU-tól, ahol a több utasítás egyidejűleg a végrehajtás különböző szakaszaiban lehet.
A különböző alternatív technikák nem zárják ki egymást - kombinálhatók (és gyakran kombinálják is) egyetlen processzorban, így lehetséges olyan többmagos CPU-t tervezni, ahol minden egyes mag egy független processzor több párhuzamos szuperskaláris pipelines processzorral. Egyes többmagos processzorok vektoros képességgel is rendelkeznek.
Kapcsolódó oldalak
- Párhuzamos számítástechnika
- Utasításszintű párhuzamosság
- Egyidejű többszálú futás (SMT)
- Többmagos processzorok
Kérdések és válaszok
K: Mi az a szuperskalár technológia?
V: A szuperskalár technológia az alapvető párhuzamos számítástechnika egy olyan formája, amely lehetővé teszi, hogy egynél több utasítás feldolgozása történjen minden egyes órajelciklusban több végrehajtó egység egyidejű használatával.
K: Hogyan működik a szuperskalár technológia?
V: A szuperskalár technológia során az utasítások sorrendben érkeznek a processzorba, futás közben keresik az adatfüggőségeket, és minden egyes órajelciklusban egynél több utasítást töltenek be.
K: Mi a különbség a skaláris és a vektoros processzorok között?
V: Egy skalár processzoron az utasítások általában egy vagy két adatelemmel dolgoznak egyszerre, míg egy vektorprocesszoron az utasítások általában sok adatelemmel dolgoznak egyszerre. A szuperskalár processzor a kettő keveréke, mivel minden utasítás egy adatelemet dolgoz fel, de egyszerre több utasítás is fut, így a processzor egyszerre sok adatelemet dolgoz fel.
K: Milyen szerepet játszik egy pontos utasításelosztó egy szuperskalár processzorban?
V: A pontos utasításelosztó nagyon fontos egy szuperskalár processzor számára, mivel biztosítja, hogy a végrehajtó egységek mindig olyan munkával legyenek elfoglalva, amelyre valószínűleg szükség lesz. Ha az utasítás-diszpatcher nem pontos, akkor a munka egy részét esetleg el kell dobni, ami miatt a processzor nem lesz gyorsabb, mint egy skálázó processzor.
K: Melyik évben vált minden normál CPU szuperskalárissá?
V: Az összes normál CPU 2008-ban vált szuperskalárissá.
K: Hány ALU, FPU és SIMD egység lehet egy normál CPU-ban?
V: Egy normál CPU-n legfeljebb 4 ALU, 2 FPU és 2 SIMD egység lehet.
Kapcsolódó cikkek
Szerző
AlegsaOnline.com Szuperskalár processzor: definíció, működés és előnyök Leandro Alegsa
URL: https://hu.alegsaonline.com/art/95080